一、項(xiàng)目背景與目標(biāo)
隨著互聯(lián)網(wǎng)信息的爆炸式增長(zhǎng),獲取特定領(lǐng)域的專家信息(如高校導(dǎo)師信息)對(duì)于學(xué)術(shù)研究、企業(yè)合作及學(xué)生報(bào)考等具有重要意義。本項(xiàng)目旨在通過(guò)Python網(wǎng)絡(luò)爬蟲(chóng)技術(shù),系統(tǒng)性地爬取山東大學(xué)機(jī)械工程學(xué)院官網(wǎng)上的所有導(dǎo)師完整信息,包括但不限于姓名、職稱、研究方向、聯(lián)系方式、教育背景、學(xué)術(shù)成果等,并將其結(jié)構(gòu)化存儲(chǔ)。作為網(wǎng)頁(yè)制作及網(wǎng)絡(luò)工程技術(shù)咨詢服務(wù)的一部分,本文將探討在合法合規(guī)的前提下,如何高效、穩(wěn)定地完成此類數(shù)據(jù)采集任務(wù),并為相關(guān)技術(shù)需求提供解決方案。
二、技術(shù)選型與準(zhǔn)備工作
- 核心工具:Python 3.x,因其豐富的庫(kù)生態(tài)系統(tǒng),是網(wǎng)絡(luò)爬蟲(chóng)開(kāi)發(fā)的首選。
- 關(guān)鍵庫(kù):
requests/aiohttp:用于發(fā)送HTTP請(qǐng)求,獲取網(wǎng)頁(yè)HTML內(nèi)容。aiohttp支持異步,適合大規(guī)模頁(yè)面抓取以提高效率。
BeautifulSoup/lxml:用于解析HTML/XML文檔,提取所需數(shù)據(jù)。
pandas:用于數(shù)據(jù)清洗、整理和存儲(chǔ)(如導(dǎo)出為CSV或Excel文件)。
re:正則表達(dá)式庫(kù),輔助提取復(fù)雜文本信息。
- 環(huán)境配置:確保安裝上述庫(kù),可使用pip命令進(jìn)行安裝。
- 法律與道德考量:在爬取前,務(wù)必查看目標(biāo)網(wǎng)站的
robots.txt文件(通常位于網(wǎng)站根目錄,如https://www.mech.sdu.edu.cn/robots.txt),尊重網(wǎng)站的爬蟲(chóng)協(xié)議。避免過(guò)高頻率的請(qǐng)求,以防對(duì)服務(wù)器造成壓力,建議設(shè)置請(qǐng)求間隔(如使用time.sleep())。僅收集公開(kāi)信息,不用于商業(yè)牟利或惡意用途。
三、爬蟲(chóng)設(shè)計(jì)與實(shí)現(xiàn)步驟
- 頁(yè)面分析:
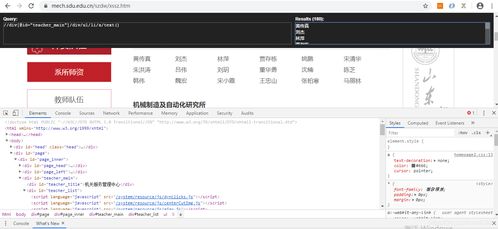
- 訪問(wèn)山東大學(xué)機(jī)械工程學(xué)院官網(wǎng),找到導(dǎo)師信息頁(yè)面(通常位于“師資隊(duì)伍”或“教師名錄”欄目)。
- 分析頁(yè)面結(jié)構(gòu):確定是靜態(tài)頁(yè)面還是動(dòng)態(tài)加載(如通過(guò)JavaScript)。可通過(guò)瀏覽器開(kāi)發(fā)者工具(F12)查看網(wǎng)絡(luò)請(qǐng)求,若數(shù)據(jù)通過(guò)XHR/Fetch請(qǐng)求獲取,則需分析API接口。
- 假設(shè)為靜態(tài)頁(yè)面,使用
requests.get()獲取HTML,并用BeautifulSoup解析。
- 數(shù)據(jù)提取:
- 定位導(dǎo)師列表的HTML元素(如
<div class="teacher-list">或<table>),提取每個(gè)導(dǎo)師的詳情頁(yè)鏈接或直接信息。
- 遍歷每個(gè)導(dǎo)師條目,進(jìn)一步訪問(wèn)詳情頁(yè)以獲取完整信息。
- 編寫解析函數(shù),使用CSS選擇器或XPath提取字段,例如:
`python
name = soup.selectone('.teacher-name').text.strip()
researcharea = soup.select_one('.research-field').text.strip()
`
- 數(shù)據(jù)存儲(chǔ):
- 將提取的數(shù)據(jù)暫存為字典或列表,最終使用
pandas.DataFrame轉(zhuǎn)換為表格。
- 導(dǎo)出為CSV文件,如
sdu<em>mech</em>teachers.csv,便于后續(xù)分析或?qū)霐?shù)據(jù)庫(kù)。
- 異常處理與優(yōu)化:
- 添加
try-except塊處理網(wǎng)絡(luò)超時(shí)、頁(yè)面不存在等異常。
- 使用User-Agent頭部模擬瀏覽器訪問(wèn),避免被屏蔽。
- 考慮使用代理IP池和異步請(qǐng)求(如
aiohttp+asyncio)以提升爬取速度。
四、網(wǎng)頁(yè)制作與網(wǎng)絡(luò)工程技術(shù)咨詢服務(wù)
在完成數(shù)據(jù)爬取后,這些信息可應(yīng)用于多種場(chǎng)景,本咨詢服務(wù)可提供以下支持:
- 數(shù)據(jù)展示網(wǎng)站開(kāi)發(fā):基于爬取的導(dǎo)師信息,構(gòu)建一個(gè)交互式網(wǎng)頁(yè),實(shí)現(xiàn)搜索、篩選和詳情查看功能。技術(shù)棧可包括HTML/CSS/JavaScript前端,以及Flask或Django后端框架,結(jié)合數(shù)據(jù)庫(kù)(如MySQL或SQLite)存儲(chǔ)數(shù)據(jù)。
- API接口設(shè)計(jì):將數(shù)據(jù)封裝為RESTful API,供第三方應(yīng)用調(diào)用,便于集成到學(xué)術(shù)平臺(tái)或移動(dòng)應(yīng)用中。
- 網(wǎng)絡(luò)工程優(yōu)化:針對(duì)爬蟲(chóng)項(xiàng)目,提供服務(wù)器部署、反爬蟲(chóng)策略規(guī)避、分布式爬蟲(chóng)設(shè)計(jì)等咨詢服務(wù),確保長(zhǎng)期穩(wěn)定運(yùn)行。
- 數(shù)據(jù)安全與合規(guī):指導(dǎo)如何加密存儲(chǔ)敏感信息(如聯(lián)系方式),并遵循GDPR等數(shù)據(jù)保護(hù)法規(guī)。
- 維護(hù)與更新:設(shè)計(jì)定時(shí)爬蟲(chóng)任務(wù)(如使用
cron或Celery),定期更新導(dǎo)師信息,保持?jǐn)?shù)據(jù)時(shí)效性。
五、
本項(xiàng)目展示了如何利用Python爬蟲(chóng)技術(shù)從山東大學(xué)機(jī)械工程學(xué)院官網(wǎng)獲取導(dǎo)師信息,并提供了從數(shù)據(jù)采集到應(yīng)用開(kāi)發(fā)的完整技術(shù)鏈。在實(shí)際操作中,需持續(xù)關(guān)注網(wǎng)站結(jié)構(gòu)變化,調(diào)整爬蟲(chóng)代碼。網(wǎng)頁(yè)制作及網(wǎng)絡(luò)工程技術(shù)咨詢服務(wù)可幫助用戶將原始數(shù)據(jù)轉(zhuǎn)化為有價(jià)值的產(chǎn)品,提升信息利用效率。通過(guò)合法合規(guī)的技術(shù)手段,我們能夠促進(jìn)學(xué)術(shù)資源的共享與創(chuàng)新。
注意:本文為技術(shù)指導(dǎo),具體實(shí)施時(shí)請(qǐng)確保獲得相關(guān)網(wǎng)站許可,并遵守法律法規(guī)。如有疑問(wèn),可聯(lián)系專業(yè)網(wǎng)絡(luò)工程團(tuán)隊(duì)進(jìn)行咨詢。